Circadian Phase Estimation and Deep Learning
Circadian Phase Estimation and Deep Learning
One of the most common questions we get at Arcascope is:
“Can’t you just do circadian phase estimation using machine learning?”
Living in the data age, we have become used to thinking that big data and machine learning can do just about anything. In this post, I will break down some of the unique challenges for circadian phase estimation with an eye towards machine learning techniques. I’ll also do a brief review of the previous attempts to apply machine learning to this task.

Big data
The last ten years have seen a tremendous proliferation and popularization of commercial wearable devices. These devices provide varying collection protocols but will generally provide time-series data for activity (steps) and heart rate measurements.
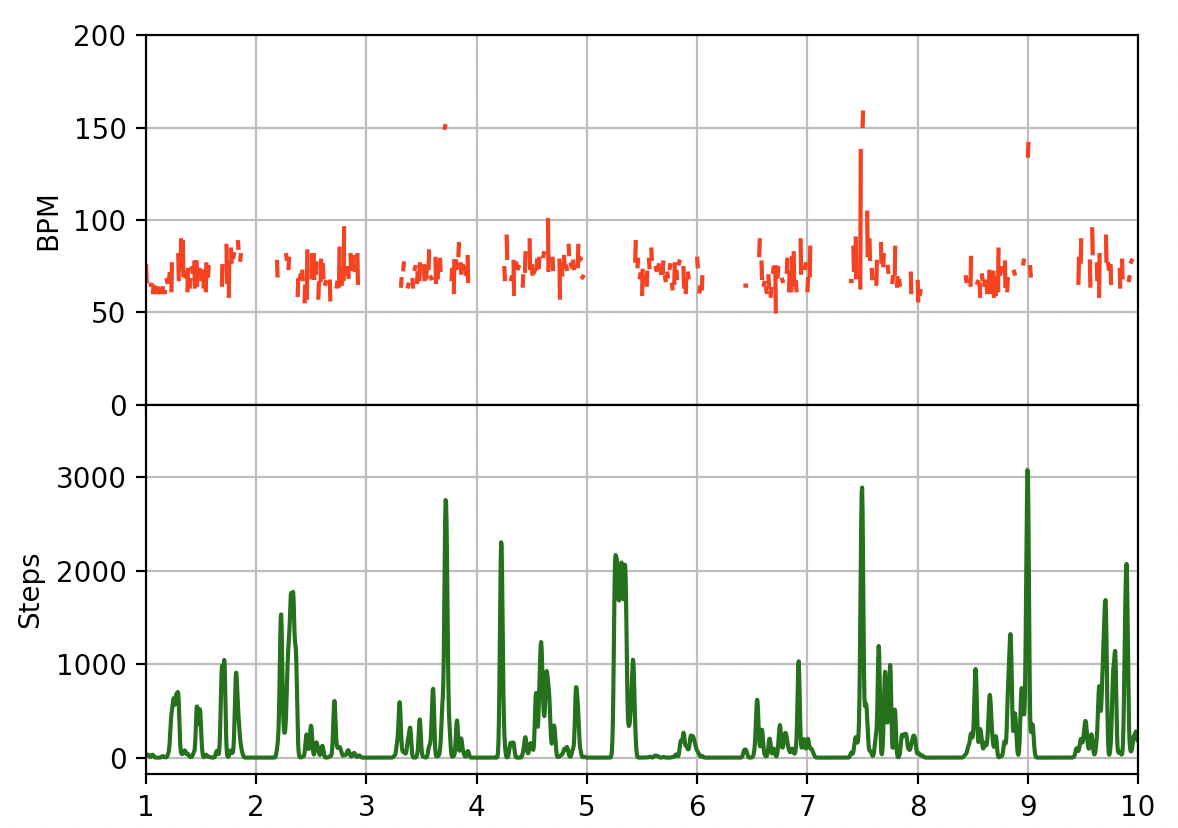
Figure 1: Example wearable data for steps and heart rate collected by an Apple Watch
This can produce an enormous amount of data over time. I can imagine that wearable data repositories at companies like Fitbit and Garmin must contain truly enormous amounts of data of this sort. Even taken individually (longitudinally) this data can be BIG, with some users having years of measurements of activity and heart rate. With this kind of scale, it is natural to think that machine learning and in particular deep learning might be the solution.
Characteristics of Wearable Data
Wearable datasets have a few characteristics which make them challenging to work with. This can restrict the machine learning tools available in real-world applications, so they bear mentioning now.
- Missing data: These data sets will have large percentages of missing data. Depending on the device, the charging time alone will introduce periodic missing data. Moreover, this missing data is non-random and typically is unmarked. Meaning that from the perspective of an algorithm it is impossible to know whether no steps were reported for a time interval because the subject was stationary or because they removed the device to charge.
- Irregular Samples: The timepoints for the data are irregularly spaced for many devices. This makes the application of recurrent neural networks (RNNs) and classical time-series methods more difficult.
- Unlabeled: The most critical shortfall of wearable data sets for circadian estimation is the lack of ground truth measurements of the internal circadian clock. More about this later.
- Individual Variability: The circadian response to the same environmental conditions varies strongly amongst individuals; therefore, to achieve high accuracy, models must account for this. This limits how data can be pooled across individuals in the learning process.
The Core Issue:
Wearable data provides noisy measurements of outputs of the circadian clock, such as sleep-wake cycles and heart rate rhythms. Each of these signals contains circadian rhythm signatures, but these signals can be easily swamped out by the host of other factors which can influence the signal.
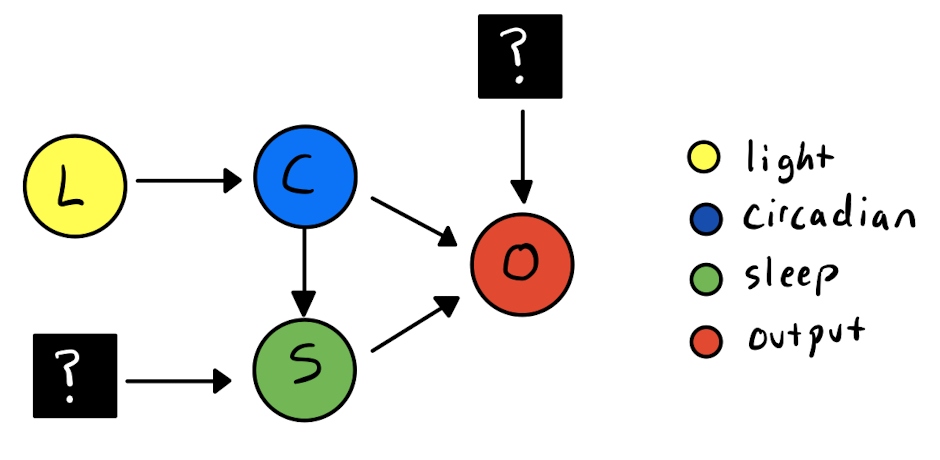
Figure 2: Causal Graph for wearable data. Arrows indicate a causal association between the variables.
This diagram needs some explanation. The arrows indicate a causal relationship between the variables. First, consider the direct path from the input light to the output measurement including our latent(hidden) circadian state. The black question mark boxes indicate factors which aren’t tracked by the wearable device but influence the rhythm. For example, starting a stressful exam might elevate your heart rate, but this change would not be accounted for in the wearable data. The same outside effects will influence the sleep state; for example, if a user is awoken by noisy neighbors the cause of this disruption would not be tracked by the wearable.
Focusing only the direct chain of causality (circled below) in this diagram is a siren song which has lured many researchers onto the rocks.
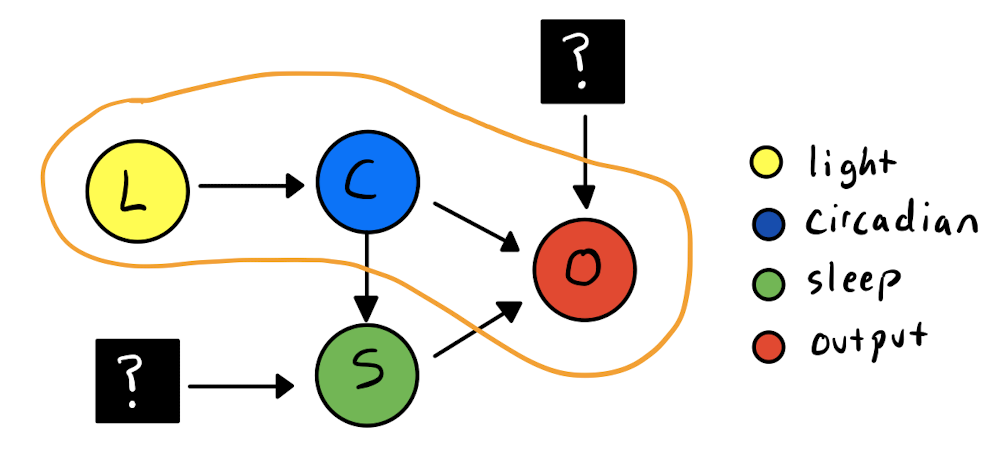
Figure 3 The direct path between inputs and outputs which is assumed by a machine learning model
The direct causal chain would be an ideal candidate for statistical and machine learning models. For example, given this data we could imagine creating an artificial neural network to model the latent circadian phase state. Models trained directly on this data will end up predominantly tracking the sleep-wake cycle. This occurs because the sleep-wake effects on the outcome variable are often quite strong and because the sleep-wake rhythm is highly correlated with the circadian rhythm. This correlation is truly insidious; it means that even if we can isolate the sleep component from our outcome variable, removing it might also remove the circadian component. With enough data, you can probably train a model which is good at predicting the outcome variable, but you won’t be building an estimate of the circadian phase.

Another potential approach is to control (condition) on the sleep variable. However, the sleep measurements collected by wearables are essentially a processed version of this outcome variable (heart rate, steps, accelerometer data). So, this approach suffers from the same flaws as the unconditioned model– except we have managed to complicate our causal diagram further without addressing the core issue.
Is the situation hopeless?
The masking effects of sleep on physiological markers for human circadian rhythms has a long history in the scientific literature (Mills et al 1978). For many years, the confounding effects of the sleep-wake cycle held up progress in the field. However, the solution came in the form of what is called a constant routine procedure. In a constant routine protocol subjects are brought into the lab for circadian phase estimation. All exogenous time signals are removed (meals, light cycle, posture changes) and the subjects are typically kept awake for periods exceeding 24 hours (Duffy et al 2002). This strict protocol removes the sleep variables and limits the black box factors in the circadian phase.
This gives the gold standard for circadian phase estimation but it is easy to see how this procedure will never scale in proportion to the big data we have available from wearable devices. Through publicly available data, academic collaborators and data collected by Arcascope we have access to hundreds of these gold standard data points. This is the small data set which can be used to train the models. Typically, this data will involve 1-2 weeks of wearable data alongside a single measurement of the circadian phase performed in the laboratory.
A Big-Small data problem
Therefore, we really have two problems: A big data problem where the data is unlabeled and confounded with the sleep-wake cycle and other masking factors, and a small data problem with only a small number of measurements and relatively short wearable time series.
Machine learning on the small data
Applying the naïve machine learning models to these smaller data sets has led to impressive results for subjects whose sleep correlates well with their circadian phase (Stone et al 2019, Brown et al 2021). However, none of these methods have generalized well when applied to new subjects or when presented with data for subjects with significant circadian disruptions (Stone et al 2019, Brown et al 2021).
For example, the below figure shows the predicted circadian marker against the measured value using a close adaptation of the feedforward neural network described in (Stone et al 2019).
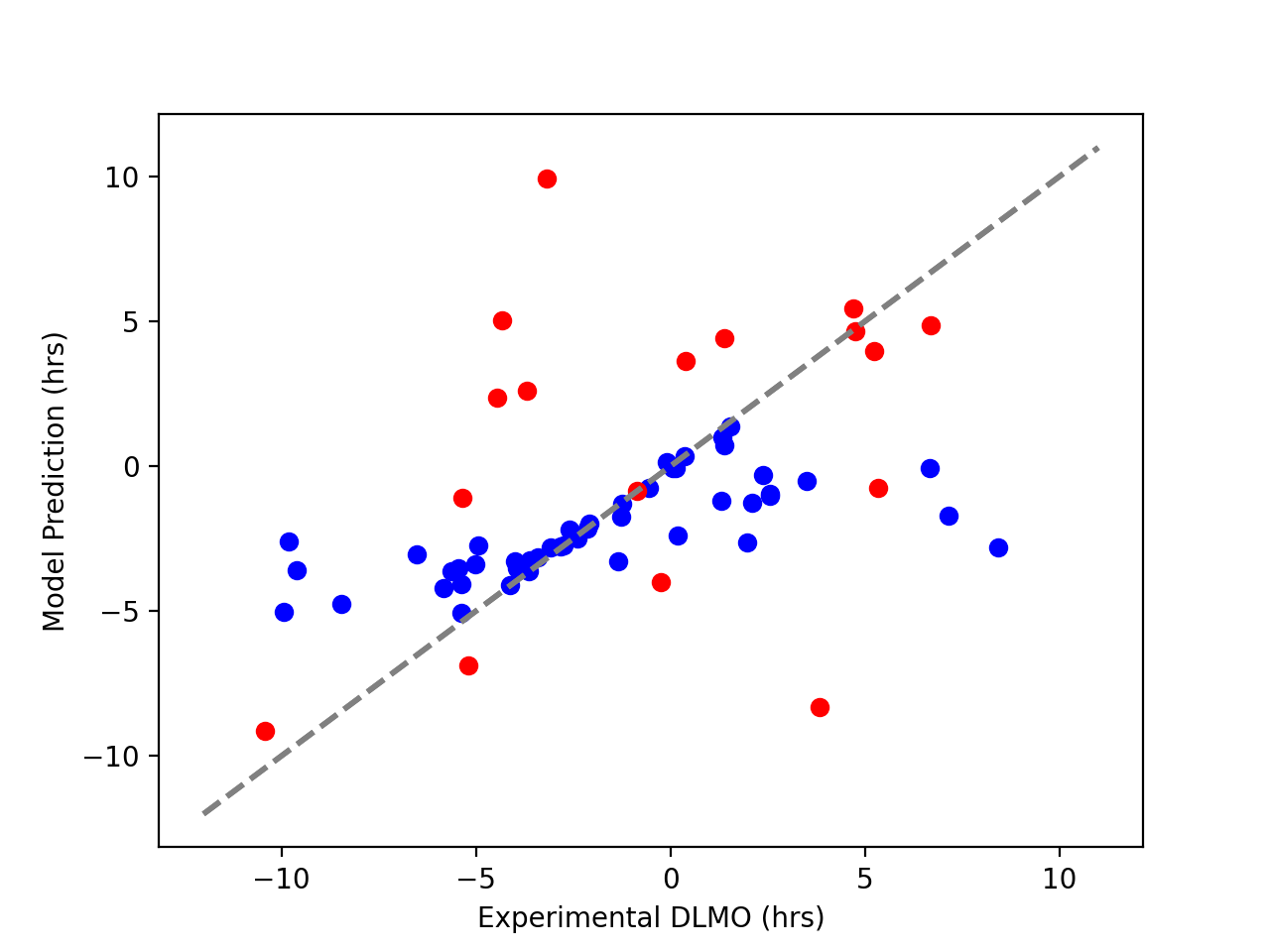
Figure 4 Feedforward neural network applied to wearable data for shift workers. The x axis shows the true circadian phase and the y-axis the model prediction. Blue dots show the training data and red dots the validation set. The predictions generalize poorly when applied to new data, as is expected for a model which is overfit.
The training error is low, but the error on the validation set is near 6 hours (which is no better than random guessing). These results mirror those reported by the authors when applying the machine learning model to disrupted individuals. This gap between the trained and validation set is characteristic of overfit models, which is hardly surprising because these models usually have more (or many more) parameters than data points (Brown et al 2021).
Moreover, since these models have been crafted on small data sets collected by paid participants, they tend to be highly data set dependent and do not deal well with irregularly sampled, non-random missing data collected by commercial wearable devices., These data sets usually include extra dimensions in the time series data (body temperature, spectral light information) which are not found on most commercial wearable devices. Finally, these studies apply stringent data exclusion policies which remove any participants with missing data above a stringent threshold. Application of these criteria to commercial wearable data would likely involve throwing much of the data out.
Machine learning on the big data
As discussed above these models will learn to predict the outcome variable by principally tracking the sleep-wake cycle. Any estimate of the circadian phase will be buried in the hidden layers of the network, meaning the results cannot be compared with the small data to check for accuracy.
Our approach
The approach we have applied at Arcascope is to blend these two approaches. The pure machine learning approach attempts to learn both the model structure and the parameters. This data-driven approach is ideal in situations with labeled big data and where we have little prior understanding of the phenomena. For example, if you are building a deep learning model to distinguish between photos of cats and dogs, you don’t have any physical or biological foundation to start from. In this case it makes sense to provide the algorithm with a general class of functions to choose from when training the network. Although, even in this case you will get the best results using a convolutional neural network, which can be seen as infusing the problem with some prior knowledge.
However, in the case of circadian biology, we understand quite a bit about the underlying biological processes and mechanisms (Nobel prize in 2017). We have developed mathematical techniques for reducing high dimensional models for the clock down to low-dimensional macroscopic models whose parameters and variables have biological meaning (Hannay et al 2018). These models can then be fit and calibrated to the gold-standard (small) data (Hannay et al 2019). This information can be leveraged to reduce the dimensionality of the search space and which allows us to link the latent variables of the machine learning model with the physiological variables of the small-data model.
This approach of blending machine learning with traditional mathematical modeling has been applied to many other problems. This chimera linking the power of both approaches is part of the secret sauce which makes our circadian phase estimates so accurate.